Advertisement
Getting machines to understand what people actually want is harder than it sounds. Most AI systems are trained using data like clicks or ratings, which only hint at human intent. But these signals can be messy. Direct Preference Optimization (DPO) offers a more focused way to train models using clear human choices. It doesn’t rely on indirect feedback.
It learns straight from comparisons, where someone picks one response over another. That kind of training helps AI respond in ways that better match what people are really looking for, especially in tasks where quality is subjective or hard to measure.
Traditional methods, such as Reinforcement Learning with Human Feedback (RLHF), involve multiple steps. First, a reward model is trained on human preference data. Then, that model is used to guide a language model using reinforcement learning. While effective, this approach adds complexity and can introduce bias if the reward model fails to accurately capture human values.
DPO skips the reward model step. Instead of turning preferences into scores, it uses them directly to train the model. Given two answers to the same prompt and knowing which one a human prefers, DPO adjusts the model so it becomes more likely to choose that kind of answer in the future. This direct use of preference data is what sets it apart.
By removing the reward modeling step, DPO avoids extra noise. It deals directly with what users choose without guessing their reasons. This makes training more stable and easier to manage, especially for language models handling tasks like writing, summarizing, or generating helpful responses.
DPO treats preferences as comparisons, not absolute ratings. That makes it well-suited for fine-tuning models in ways that reflect subtle human judgments—whether a sentence feels polite, a summary is clear, or an explanation is helpful. Where traditional reward functions might miss the nuance, direct comparisons preserve it.
Standard reinforcement learning setups, including RLHF, need three parts: preference data, a reward model, and a training algorithm like PPO. Each layer introduces uncertainty. The reward model might not generalize well. The optimization phase might push the model too far from its original version.
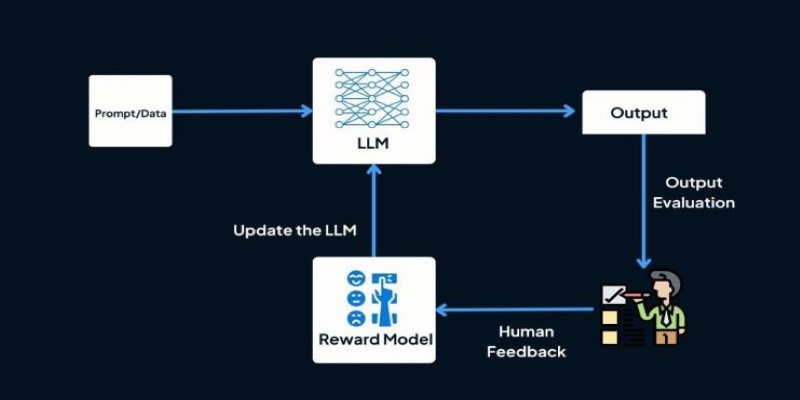
DPO cuts this down. It learns straight from the comparison data. No value estimation, no simulated environments, and no tricky tuning of reward weights. It just updates the model based on which choice humans prefer. This stripped-down process makes it faster and more direct.
Optimization in DPO is simpler. It doesn’t require reward balancing or trade-offs in exploration. It uses a contrastive objective that encourages the model to prefer the better answer from each comparison pair. This not only makes training easier but can also reduce unexpected behavior, especially when models are fine-tuned on subjective tasks.
This method works especially well in areas where feedback isn’t numeric. If people are judging tone, helpfulness, or relevance, DPO captures that better than trying to assign scores. By learning from actual preferences, it creates more natural and user-aligned responses.
Large language models, such as GPT, are already being fine-tuned using ideas based on DPO. These models generate text for various purposes, including answers, explanations, summaries, and more. Since the quality of these outputs depends on human judgment, preference data is more useful than fixed metrics.
In training, DPO takes human choices between responses and improves the model, so it prefers the more helpful or accurate one. This makes a difference in tasks where there's no single correct answer. Summarization, translation, and conversational replies all benefit from this kind of tuning.
Another benefit is in handling sensitive content. If users find a certain output inappropriate or unclear, they can mark a better alternative. DPO picks up on that and adjusts the model accordingly. This helps reduce toxic or biased replies without relying on hand-written rules.
Beyond text, any AI that generates results based on judgment—like recommendations or planning tools—can benefit. If users choose between two suggestions, DPO can guide the system using that choice without needing complex scoring rules.
Its simplicity makes it a good choice for teams aiming to improve AI behavior with fewer moving parts. Especially in cases where collecting large amounts of reliable comparison data is feasible, DPO provides a direct path from preference to improved output.
Direct Preference Optimization brings a cleaner approach to model alignment. Instead of estimating rewards or relying on complex reinforcement learning loops, it connects human choices directly to training signals. That helps avoid confusion and results in models that behave more predictably and usefully.

The method is especially promising in large-scale fine-tuning. When models are being prepared for general use, training them with preference data helps them respond more naturally. And since DPO is easier to scale, it fits well in training pipelines focused on user interaction.
Of course, it depends on good data. If the preferences used in training are biased or narrow, the model will reflect that. But compared to systems that use an extra layer of reward modeling, DPO gives fewer chances for that bias to grow.
There’s also the advantage of speed. Without needing to build and maintain a separate reward model, teams can move faster from data collection to model improvement. That makes DPO an attractive tool for developers aiming to build AI that adapts well to user needs.
Its main strength lies in its simplicity. By taking human choices at face value and using them directly, DPO avoids overcomplication. That makes it useful not just for chatbots or content generation but for any AI system that needs to act in line with how people think.
Direct Preference Optimization simplifies AI training by using human comparisons instead of layered scoring systems. It helps models learn directly from user choices, especially in areas where quality can't be measured by numbers. This approach is already improving language models and is expected to see wider use as AI tools become more common. While not a complete solution, DPO gives AI a better shot at understanding and adapting to what people actually want from their interactions.
Advertisement

How to create Instagram Reels using Predis AI in minutes. This step-by-step guide shows how to turn ideas into high-quality Reels with no editing skills needed

Explore key features, top benefits, and real-world use cases of OpenAI reasoning models that are transforming AI in 2025.

How Python handles names with precision using namespaces. This guide breaks down what namespaces in Python are, how they work, and how they relate to scope

Can you really run a 7B parameter language model on your Mac? Learn how Apple made Mistral 7B work with Core ML, why it matters for privacy and performance, and how you can try it yourself in just a few steps

How to fine-tune a Tiny-Llama model using Unsloth in this comprehensive guide. Explore step-by-step instructions on setting up your environment, preparing datasets, and optimizing your AI model for specific tasks

Find how Flux Labs Virtual Try-On uses AI to change online shopping with realistic, personalized try-before-you-buy experiences

Tech leaders face hurdles in developing reliable AI agents due to complexity, scalability, and integration issues.
What happens when you stop relying on majority vote and start using smarter label aggregation? See how Distilabel and Argilla helped build a chatbot with clearer, more consistent labels and faster feedback cycles

Reddit's new data pricing impacts AI training, developers, and moderators, raising concerns over access, trust, and openness

AWS launches AI chatbot, custom chips, and Nvidia partnership to deliver cost-efficient, high-speed, generative AI services

How DeepSeek LLM: China’s Latest Language Model brings strong bilingual fluency and code generation, with an open-source release designed for practical use and long-context tasks

Discover how clean data prevents AI failures and how Together AI's tools automate quality control processes.