Advertisement
AI models are getting smarter, but sometimes they're just too big for practical use. That's where Tiny-Llama steps in. It's a smaller, more efficient version of the original LLaMA model, built to run well even when resources are limited. You get strong performance without the heavy lift. However, to make any model truly useful, it needs to be trained on data that fits the task, and that's where fine-tuning matters.
Unsloth is a tool that makes this process easier. It strips away the extra steps and lets you focus on getting better results with less hassle. In this article, we'll look at how to fine-tune a Tiny-Llama model using Unsloth, from setup to execution, with clear steps along the way.
Tiny-Llama isn't just a downsized version of a big model—it's a smart choice for real-world projects. The original LLaMA is powerful, but its size can be a dealbreaker if you don't have access to strong hardware. Tiny-Llama gives you the core strengths in a compact format that still gets the job done.
When you fine-tune a model like that, you're instructing it to learn the language of your data. That might mean fitting it for medical notes, technology documentation, or whatever else your project requires. The model picks up the patterns, tone, and vocabulary of greatest importance. Unsloth aids in streamlining this learning process, getting you there quicker and easier without struggling with cumbersome code or setups.
Unsloth is a simple-to-use framework that aims to ease the tuning of transformer-based models such as Tiny-Llama. It provides a high-level API, abstracting away many of the complexities typically involved in model training. By leveraging Unsloth, you can focus more on the task at hand and less on the intricacies of model optimization. This is especially useful for researchers and developers who need quick iterations without deep involvement in every technical detail.

One of the key features of Unsloth is its ability to manage large datasets with minimal effort. It optimizes data handling, ensuring that your model receives the right kind of data for fine-tuning. Additionally, Unsloth supports distributed training, which allows you to speed up the fine-tuning process by leveraging multiple GPUs.
To fine-tune a Tiny-Llama model using Unsloth, there are several steps involved. These steps ensure that the model is properly trained to understand your specific dataset and perform the desired tasks.
The first step is to set up your working environment. Make sure you have Python installed along with the necessary libraries. You'll need libraries like PyTorch, transformers, and Unsloth. Installing Unsloth can be done through pip:
bash
CopyEdit
pip install unsloth
Once your environment is ready, you can proceed with downloading the pre-trained Tiny-Llama model. The easiest way to get this is through the Hugging Face model hub. With just a few lines of code, you can load Tiny-Llama:
python
CopyEdit
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("tiny-llama")
tokenizer = AutoTokenizer.from_pretrained("tiny-llama")
The next step is preparing the dataset you'll use for fine-tuning. Your dataset must be in a format that the model can process. Typically, you'll want to tokenize your dataset using the same tokenizer that the model was originally trained with. This ensures that the input format remains consistent. Here's how you can tokenize a sample dataset:
python
CopyEdit
inputs = tokenizer("Your dataset text here", return_tensors="pt")
Unsloth makes this process even easier by allowing you to directly pass your dataset into its fine-tuning pipeline. The framework supports datasets in multiple formats, including CSV and JSON. If your data is not already tokenized, Unsloth will handle this automatically for you, ensuring that the input is properly formatted for the model.

Now that you’ve set up your environment and prepared the dataset, it’s time to configure the training parameters. This includes setting the learning rate, batch size, and the number of epochs. Unsloth provides a simple API to configure these parameters:
python
CopyEdit
from unsloth import Trainer
trainer = Trainer(
model=model,
args={
'learning_rate': 5e-5,
'batch_size': 16,
'num_train_epochs': 3,
},
train_dataset=inputs,
)
Unsloth also allows you to fine-tune specific layers of the model, which is useful when you're working with a small dataset or when you want to preserve certain parts of the model. This level of control makes Unsloth a versatile tool for fine-tuning.
Once everything is configured, you can start the fine-tuning process. Unsloth provides an easy-to-use training method that takes care of the training loop for you. Here's how you can fine-tune the model:
python
CopyEdit
trainer.train()
Unsloth will automatically monitor the training process, providing you with useful metrics like loss and accuracy. It also supports features like checkpointing, so you can save the model's state at regular intervals and resume training if necessary.
After the fine-tuning process is complete, it’s important to evaluate the model’s performance. You can use a validation dataset to check how well the model is performing on unseen data. Unsloth integrates seamlessly with evaluation tools, allowing you to easily track performance metrics such as perplexity or F1 score.
Moreover, Unsloth supports model quantization, which is a technique to reduce the model’s size without sacrificing too much performance. This is particularly useful when deploying Tiny-Llama to edge devices with limited resources.
Fine-tuning a Tiny-Llama model with Unsloth provides an efficient way to tailor AI models to specific needs. Its simple setup, quick training process, and robust tools help maximize Tiny-Llama's potential. Whether working with limited resources or aiming for high performance, this combination allows for streamlined fine-tuning. Unsloth makes fine-tuning Tiny-Llama ideal for a variety of tasks, from NLP to specialized applications like sentiment analysis or chatbots. The framework's ease of use and versatility make it a great choice for those looking to fine-tune models without the complexities of training.
Advertisement

Reddit's new data pricing impacts AI training, developers, and moderators, raising concerns over access, trust, and openness
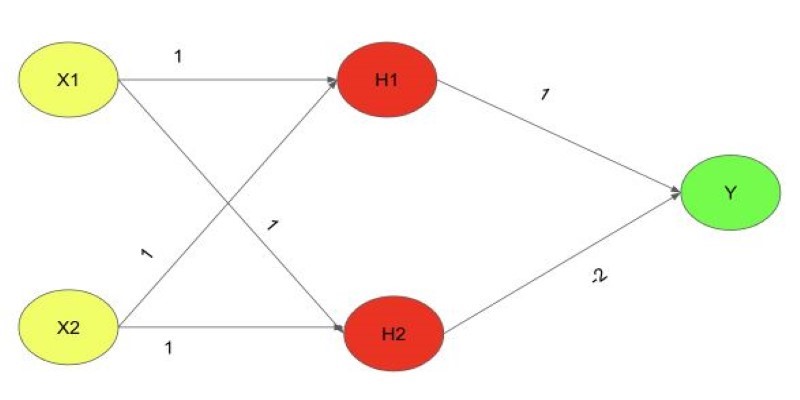
Explore the XOR Problem with Neural Networks in this clear beginner’s guide. Learn why simple models fail and how a multi-layer perceptron solves it effectively

Discover how clean data prevents AI failures and how Together AI's tools automate quality control processes.

AWS launches AI chatbot, custom chips, and Nvidia partnership to deliver cost-efficient, high-speed, generative AI services

Explore key features, top benefits, and real-world use cases of OpenAI reasoning models that are transforming AI in 2025.

Can you really run a 7B parameter language model on your Mac? Learn how Apple made Mistral 7B work with Core ML, why it matters for privacy and performance, and how you can try it yourself in just a few steps
What happens when you stop relying on majority vote and start using smarter label aggregation? See how Distilabel and Argilla helped build a chatbot with clearer, more consistent labels and faster feedback cycles

What if you could deploy dozens of LoRA models with just one endpoint? See how TGI Multi-LoRA lets you load up to 30 LoRA adapters with a single base model

RAG combines search and language generation in a single framework. Learn how it works, why it matters, and where it’s being used in real-world applications

Tech leaders face hurdles in developing reliable AI agents due to complexity, scalability, and integration issues.

How Python’s classmethod() works, when to use it, and how it compares with instance and static methods. This guide covers practical examples, inheritance behavior, and real-world use cases to help you write cleaner, more flexible code

Learn how DreamBooth fine-tunes Stable Diffusion to create AI images featuring your own subjects—pets, people, or products. Step-by-step guide included