Advertisement
China has introduced a new contender in the language model landscape. DeepSeek LLM enters with an open-source approach, multilingual focus, and solid technical design. Built by the DeepSeek team, it isn’t just a GPT variant—it’s trained with more data, longer context, and tuned for code and language tasks.
While global attention often centers around American labs, DeepSeek signals that China is shaping its direction in AI. This release is more than a tech showcase—it's a sign that Chinese research teams are ready to compete on function, accessibility, and real-world performance.
DeepSeek LLM comes in two sizes: 7B and 67B parameters. These sizes make it flexible for developers while offering enough capacity for larger tasks. The model follows a decoder-only transformer structure, with some improvements aimed at smoother inference and memory usage.
What really sets it apart is the dataset—2.4 trillion tokens across Chinese, English, and code, with a context window of 32k tokens. That long context makes the model ideal for handling extended conversations, document summaries, and retrieval applications that need to look back further than most models allow.
The model was trained on local compute clusters in China, using GPUs that avoid international supply issues. Rather than chasing extreme parameter counts, the team focused on better data curation, tuning, and practical inference. This makes the model more stable in usage and gives it a stronger grip on multi-turn tasks.
DeepSeek LLM doesn’t feel like an experiment—it feels like it was made to be used. The model can maintain instruction accuracy, hold threads across long spans, and answer consistently within its trained scope. This practical focus is a key part of what separates it from more experimental open models.
DeepSeek LLM handles Chinese language tasks with a high level of fluency. Many English-trained models fall short when switching to Chinese, often producing odd syntax or broken idioms. DeepSeek doesn’t stumble there. It writes clean sentences, keeps tone control, and responds well to follow-up queries in Chinese.

English support is also reliable. It performs comparably to open models like LLaMA 2 and Mistral, especially in general-purpose question answering. It may not outperform every model in benchmarks, but for day-to-day uses, it’s consistent and coherent.
Code generation is another strong point. The model works well across Python, JavaScript, and C++. It can debug, suggest code completions, and translate tasks written in natural language into working scripts. Its output avoids frequent hallucinations, maintains indentation, and usually understands the goal of the prompt. This makes it a good tool for developers to build prototypes or tools inside IDEs.
The training focus on GitHub-level repositories helps DeepSeek LLM hold its own against dedicated code models like StarCoder. It may not replace a specialized coder model, but it’s close enough for most mixed-language and multi-task applications.
DeepSeek LLM is fully open-source. The model weights, training logs, and tokenizer are all available, including an instruction-tuned version. Few large models from China have taken this route, making DeepSeek’s release a landmark in public AI tools from the region.
A vision-language extension called DeepSeek-VL was also released, allowing the model to handle images and text together. It performs reasonably in tasks like captioning and image Q&A, using a CLIP-style encoder combined with DeepSeek's textbase.
Even with its open release, DeepSeek applies reasonable restrictions. The license blocks harmful use cases. This balanced approach offers public access while acknowledging the risks of misuse.
The decision to release it openly benefits research, especially for those working with Chinese-language tools. Enterprises looking to run private models without latency or cloud dependency now have a strong bilingual option. For startups, it lowers the entry cost to deploy a capable LLM locally or on a modest infrastructure.
While many open models aim to match GPT-3.5 in general intelligence, DeepSeek’s value comes from stability and multilingual function. It doesn’t overpromise, but it rarely misfires. That reliability is important for systems that need predictable answers, not flashy ones.
DeepSeek LLM scores well on standard tests. It beats many open models in its category on MMLU and HumanEval. Though it doesn’t match GPT-4, its consistency across benchmarks makes it more reliable in practical settings. It doesn’t excel in one area and fail in others—it keeps a steady output across the board.

The model is already used in chat assistants, search, and content generation tools. In education, it's being tested for student support, while businesses use it for meeting summaries and client communications. Its ability to manage longer dialogues and understand both Chinese and English gives it an edge in bilingual markets.
Legal and policy tools have also started using DeepSeek LLM. It can read, summarize, and explain lengthy government texts. For tech support and internal help bots, the model handles long workflows and instructions with clarity. These applications benefit more from its long context and clear outputs than from raw benchmark scores.
A larger 130B model is rumored to be in the works. There’s also work on fine-tuning smaller versions for edge devices. Instead of following the trend of building ever-larger models, DeepSeek’s team seems focused on more useful ones—those that work better with fewer tokens, lower latency, and better alignment.
While many labs push for the biggest models possible, DeepSeek is going a different route. It’s choosing longer context, better code understanding, and bilingual fluency over sheer size. That choice makes it easier to use and integrate into existing systems.
DeepSeek LLM represents a meaningful shift in how large models are developed and released. Built-in China, fluent in both Chinese and English and strong in code, it fills gaps left by other open models. With long context windows and stable outputs, it suits real-world tasks instead of just demos. Its open-source license allows more developers to experiment, fine-tune, and build on top without heavy infrastructure or locked-down APIs. While it doesn't aim to be the biggest, DeepSeek LLM proves that focused design can matter more than raw size. It's a clear sign that China's AI scene is growing up—quickly and in its own way.
Advertisement

Still unsure about Git push and pull? Learn how these two commands help you sync code with others and avoid common mistakes in collaborative projects
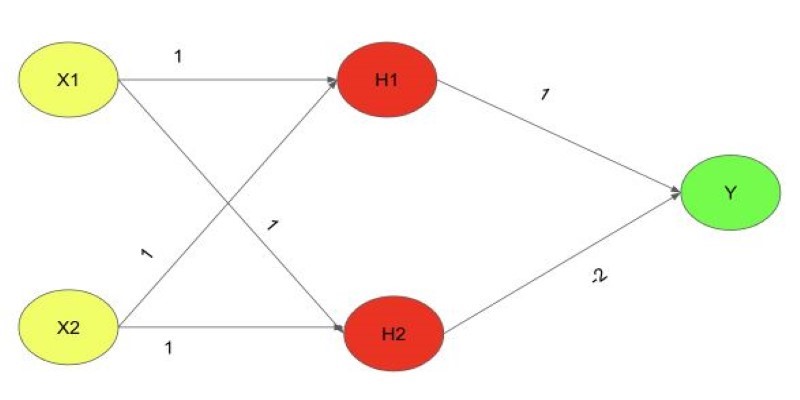
Explore the XOR Problem with Neural Networks in this clear beginner’s guide. Learn why simple models fail and how a multi-layer perceptron solves it effectively

Find how Flux Labs Virtual Try-On uses AI to change online shopping with realistic, personalized try-before-you-buy experiences

Gemma 3 mirrors DSLMs in offering higher value than LLMs by being faster, smaller, and more deployment-ready

NPC-Playground is a 3D experience that lets you engage with LLM-powered NPCs in real-time conversations. See how interactive AI characters are changing virtual worlds

How DeepSeek LLM: China’s Latest Language Model brings strong bilingual fluency and code generation, with an open-source release designed for practical use and long-context tasks

How Python handles names with precision using namespaces. This guide breaks down what namespaces in Python are, how they work, and how they relate to scope

Discover how OpenAI's Sora sets a new benchmark for AI video tools, redefining content creation and challenging top competitors

Reddit's new data pricing impacts AI training, developers, and moderators, raising concerns over access, trust, and openness
What happens when you stop relying on majority vote and start using smarter label aggregation? See how Distilabel and Argilla helped build a chatbot with clearer, more consistent labels and faster feedback cycles

Can you really run a 7B parameter language model on your Mac? Learn how Apple made Mistral 7B work with Core ML, why it matters for privacy and performance, and how you can try it yourself in just a few steps

Learn the top 7 impacts of the DOJ data rule on enterprises in 2025, including compliance, data privacy, and legal exposure.