Advertisement
When we began working on the next version of our chatbot, built on Argilla, we had a clear goal in mind: to reduce the manual load, speed up training, and improve model clarity through better labels. It wasn't about chasing buzzwords or bolting on extra layers. We just needed smarter labeling. That's where Distilabel came into the picture.
Argilla, on its own, gives you strong annotation workflows and visibility into data labeling quality. But as datasets grew and we introduced more nuanced feedback from annotators, we found ourselves stuck in the same loop. So, we looked at Distilabel not just as a tool but as a new backbone for managing label consolidation in a way that made sense for iterative model training.
Let’s begin with what made Distilabel stand out. At its core, it’s a library built to help you train decision-making models for label aggregation. Instead of relying on fixed majority votes or hand-crafted heuristics, you can teach it how to resolve conflicts in labels. And when your annotations come from a mix of models, humans, and templates — that matters.
We weren’t interested in building a perfect pipeline from day one. What we needed was flexibility. Distilabel gave us that by letting us build custom distillation strategies. For our case, we used it to:
There’s a difference between just tallying up votes and trying to reflect actual intent in data. With Distilabel, we could inject judgment without adding more manual review.
First, we collected responses for prompts using a mix of human reviewers and LLM-generated replies. Each prompt had at least three annotations — sometimes more, depending on ambiguity. The goal here wasn’t to chase volume but to get a broad enough view of intent and appropriateness.
All annotations were logged into Argilla, where we could track annotator ID, timestamps, explanations, and even confidence levels when available. That history turned out to be more useful than we originally thought.
Next, we created a strategy to combine all that feedback into a single, meaningful label. Here’s how it looked:
Distilabel let us train this strategy like a model. Over time, it improved at resolving common conflicts — especially in borderline helpfulness and hallucination cases.
Once we had confidence in the strategy, we applied it to the entire set of annotations to create a clean, distilled dataset. This wasn't just “one label per example.” In cases of nuanced feedback, we included metadata about uncertainty, prior conflicts, and even links to original annotations.
We versioned the datasets in Argilla and tagged them by the strategy used — so that later, we could compare the performance of models trained on different distillation approaches. This was key to our internal validation process.
The chatbot wasn’t built in one shot. After every round of training, we fed a subset of model outputs back into Argilla for fresh annotation. That meant every training loop gave us a new chance to test how well the distillation held up.
Distilabel didn’t just work on the first pass. We re-ran the strategy each time using updated signals, so the dataset evolved with the chatbot. In a way, it became the model’s memory — a smarter one that grew more consistent over time.
Before, we had to go through pages of disagreements to figure out why a certain prompt response was labeled “unhelpful” or “incorrect.” With Distilabel, we could surface explanations tied to disagreements and re-rank feedback samples for review.
This helped during the critical evaluation stage. Instead of reviewing random samples, we focused on high-uncertainty cases. And that made human reviews count more.
New reviewers didn’t have to guess what makes a good label. We shared examples from Distilabel where label decisions were weighted heavily in one direction — and explained why. It made onboarding smoother, and over time, it reduced the range of disagreements.
Because we trained the model on outputs from a controlled distillation strategy, we had a much tighter grip on where and how things were changing. We didn’t need to overhaul everything after each fine-tuning. When hallucinations or tone issues cropped up, we tracked them down to specific rounds of annotations and retrained from just those segments.
Creating the Argilla 2.0 chatbot wasn’t about scaling up for the sake of it. It was about improving the way we treat training data — with more care, more context, and less repetition. Distilabel made it possible to go beyond “pick the most common label” and toward something closer to understanding what makes a response useful.
In the end, what we got was a chatbot that reflects that same balance — clear, steady, and better at adapting to the kind of feedback that matters.
Advertisement

Understand how the Python range() function works, how to use its start, stop, and step values, and why the range object is efficient in loops and iterations
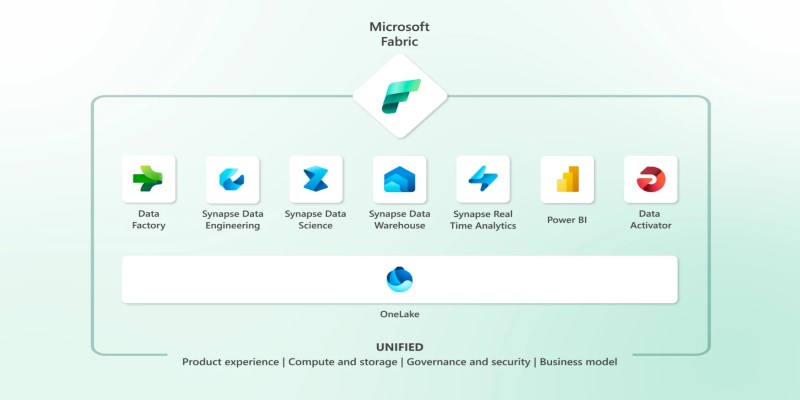
Explore Microsoft Fabric, a unified platform that connects Power BI, Synapse, Data Factory, and more into one seamless data analytics environment for teams and businesses

Learn the top 7 impacts of the DOJ data rule on enterprises in 2025, including compliance, data privacy, and legal exposure.

Tech leaders face hurdles in developing reliable AI agents due to complexity, scalability, and integration issues.

Reddit's new data pricing impacts AI training, developers, and moderators, raising concerns over access, trust, and openness

NPC-Playground is a 3D experience that lets you engage with LLM-powered NPCs in real-time conversations. See how interactive AI characters are changing virtual worlds

How to fine-tune a Tiny-Llama model using Unsloth in this comprehensive guide. Explore step-by-step instructions on setting up your environment, preparing datasets, and optimizing your AI model for specific tasks
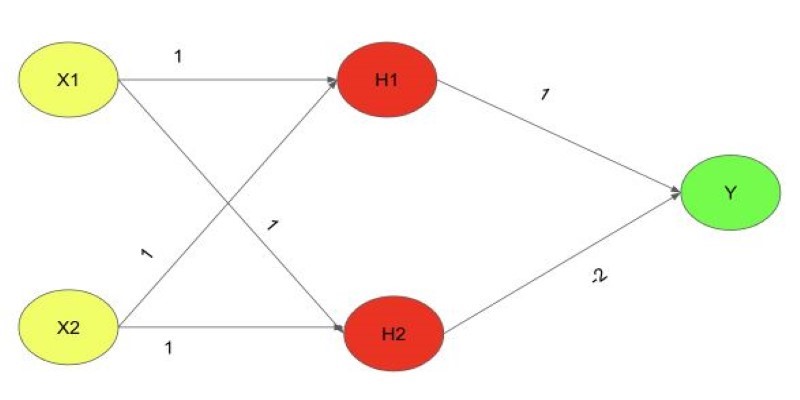
Explore the XOR Problem with Neural Networks in this clear beginner’s guide. Learn why simple models fail and how a multi-layer perceptron solves it effectively

Find how Flux Labs Virtual Try-On uses AI to change online shopping with realistic, personalized try-before-you-buy experiences

Need to convert a Python list to a NumPy array? This guide breaks down six reliable methods, including np.array(), np.fromiter(), and reshape for structured data

Discover how OpenAI's Sora sets a new benchmark for AI video tools, redefining content creation and challenging top competitors

Discover how to generate enchanting Ghibli-style images using ChatGPT and AI tools, regardless of your artistic abilities