Advertisement
Apple's WWDC 2024 brought several interesting announcements, but one that quietly turned heads was the ability to run the Mistral 7B model locally using Core ML. For those who follow the machine learning space, this is significant. We're talking about a dense language model with 7 billion parameters—running directly on a Mac. No cloud. No latency. Just raw on-device inference.
It’s the kind of update that doesn’t necessarily dominate headlines but completely reshapes how developers can think about local AI apps.
Mistral 7B is an open-weight transformer model that's trained on a large corpus of text data and designed to perform a wide range of language tasks. Think text generation, summarization, code completion, and even simple reasoning. Unlike many open-weight models, Mistral 7B stands out because it punches above its weight. It's dense, optimized, and manages to perform comparably to larger models like LLaMA 2.13 B—all while remaining more compact.
The real difference-maker, though, is how Apple’s Core ML tools have made it possible to run it locally. And yes, this includes laptops like the MacBook Air M2 and M3, which are fanless. Yet, they manage to pull it off.
Apple collaborated with the MLX framework to optimize models, such as Mistral 7B, for Apple silicon. MLX is Apple's proprietary machine learning framework, designed specifically for the CPU-GPU-Apple Neural Engine combination found in the M1, M2, and M3 chips. Unlike generic PyTorch or TensorFlow setups, MLX takes advantage of memory sharing and unified architecture across Apple hardware, so you don’t waste resources moving data between processors.

When they brought Mistral 7B to Core ML, they used quantization—specifically 4-bit and 8-bit formats—to shrink the model down to something manageable. For context, the full-precision model can eat up over 13GB of RAM. But quantized versions? You can run them on machines with 8GB or 16GB of unified memory. That's the big win here.
In testing, the model was shown to generate outputs at a rate of around 15 to 25 tokens per second on the M3 Pro. And yes, this was all done without any cloud support.
If you’re a developer or just someone curious about trying it on your Mac, you can run Mistral 7B with Core ML today. Here’s how it’s done.

Start with the Core ML version of Mistral 7B. Apple released a fully converted Core ML package at WWDC, and it’s available on Hugging Face through their partnership with the Mistral team. Look for a quantized version, either in 4-bit or 8-bit. If you’re on an M1 or lower-tier M2 device, the 4-bit version is the safest bet.
Make sure to place the downloaded .mlmodelc folder in a location where your app or playground can access it.
MLX can run natively on macOS and is optimized for Apple Silicon. You'll want to clone the official MLX GitHub repo and follow the install guide. Most of the setup involves installing the dependencies using Python and homebrew. Apple provides a sample code that demonstrates how to load and run the Mistral model using MLX. This is particularly helpful for those who want full control over inference behavior.
But if you don’t want to work directly with MLX, you can jump right into Core ML APIs from Xcode.
Step 3: Load the Model in Xcode
Create a new Swift project in Xcode. In the project navigator, drag the .mlmodelc folder into your app. Once it’s part of your project, Xcode will recognize the model and allow you to interact with it using native Swift code.
Use the MLModel class to load the model:
swift
CopyEdit
let config = MLModelConfiguration()
let model = try Mistral7B(configuration: config)
Then prepare your input prompt and feed it to the model:
swift
CopyEdit
let input = Mistral7BInput(text: "Explain how Core ML runs Mistral 7B.")
let prediction = try model.prediction(input: input)
print(prediction.output)
Of course, you’ll want to handle this with proper threading and memory handling if you’re using it in a real-time app.
Once you hit run, the model processes the input prompt and returns a text output. You can monitor memory usage using Activity Monitor or Instruments to get a sense of how much RAM and CPU/GPU is being used.
On a MacBook Air M3, you can expect around 12GB of memory usage with the 4 GB model. Token generation speeds vary depending on the temperature and complexity of the prompt, but it’s surprisingly responsive for something running on-device.
Apple isn't the first to enable on-device AI inference, but they're doing it differently. By baking support into Core ML and optimizing for their hardware stack, they've made it possible for developers to run large language models without the friction of custom GPU setups or external dependencies.
What this does is open the door for new kinds of apps—text tools, offline assistants, coding helpers—that don't need a server or internet connection to run. Think of a note-taking app that summarizes content offline or an IDE extension that provides smart suggestions even when you're on a plane. These are now possible without draining the battery or freezing your system.
And let’s not ignore the privacy angle. When inference happens locally, your text stays on your machine. That’s a big deal, especially in regulated environments or for users who are simply cautious.
WWDC 24 didn’t just show off what’s coming to iOS or visionOS. It provided developers with real tools to build smarter, faster apps without requiring cloud support. Running Mistral 7B with Core ML is a good example of that shift. It's not about hype; it's about execution. And Apple, as always, leaned into its hardware-software integration to make it a reality.
If you’ve got a Mac with Apple Silicon and some interest in machine learning, this is something worth trying out. You don’t need to be a researcher. You don’t need a data center. Just a Mac, a few lines of Swift, and a model that somehow fits into your unified memory. That’s the story.
Advertisement

Learn how DreamBooth fine-tunes Stable Diffusion to create AI images featuring your own subjects—pets, people, or products. Step-by-step guide included

Reddit's new data pricing impacts AI training, developers, and moderators, raising concerns over access, trust, and openness

Discover how OpenAI's Sora sets a new benchmark for AI video tools, redefining content creation and challenging top competitors

RAG combines search and language generation in a single framework. Learn how it works, why it matters, and where it’s being used in real-world applications

How Direct Preference Optimization improves AI training by using human feedback directly, removing the need for complex reward models and making machine learning more responsive to real-world preferences
Transform any website into an AI-powered knowledge base for instant answers, better UX, automation, and 24/7 smart support

Meta's scalable infrastructure, custom AI chips, and global networks drive innovation in AI and immersive metaverse experiences

AWS launches AI chatbot, custom chips, and Nvidia partnership to deliver cost-efficient, high-speed, generative AI services

Explore key features, top benefits, and real-world use cases of OpenAI reasoning models that are transforming AI in 2025.

Discover how clean data prevents AI failures and how Together AI's tools automate quality control processes.
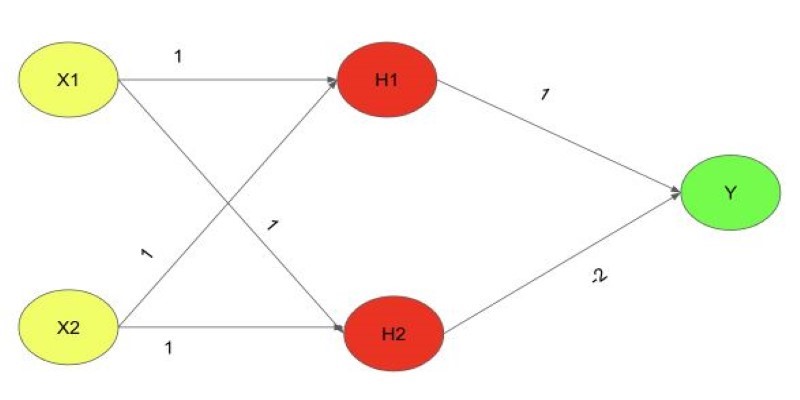
Explore the XOR Problem with Neural Networks in this clear beginner’s guide. Learn why simple models fail and how a multi-layer perceptron solves it effectively

Can you really run a 7B parameter language model on your Mac? Learn how Apple made Mistral 7B work with Core ML, why it matters for privacy and performance, and how you can try it yourself in just a few steps