Advertisement
Neural networks are often described as powerful tools that can learn about anything—until they meet something as simple as an XOR problem. For a beginner, this might sound odd. After all, if neural networks can recognize faces and translate languages, how can they struggle with a basic logical function like XOR? The truth is that XOR reveals something important about how neural networks work.
It highlights the limits of simple models and shows why certain structures are needed for learning. Understanding the XOR problem is like learning how to ride a bicycle without falling over—it lays a foundation that makes the next steps a lot easier.
To start, XOR stands for "exclusive OR." It's a simple logic function that takes two binary inputs and returns one output. The rule is to return one if exactly one of the inputs is 1; otherwise, return 0. So, (0,0) gives 0, (0,1) gives 1, (1,0) gives 1, and (1,1) gives 0. That's it. It's not a complex function, but it poses a problem for early neural networks, especially those with only one layer, known as perceptrons.
The issue comes from how data is separated. In machine learning, we often want to draw a straight line (or plane in higher dimensions) to split the data into groups. This is called linear separability. The XOR function isn’t linearly separable. If you try to draw a single straight line that separates the outputs of XOR (0 or 1), you’ll quickly realize it can’t be done. There’s no way to cut the plane to cleanly divide the 1s from the 0s using one straight line.
This limitation made XOR an important topic in the early days of neural networks. It proved that a single-layer network could not model some basic logical functions. It exposed a flaw in the early optimism around AI and led to a long pause in research known as the "AI winter." But later breakthroughs solved the XOR problem—and understanding how those solutions work can help you grasp the role of architecture in neural networks.
The first generation of neural networks relied on a simple structure called the perceptron. It’s made of input nodes, each with a weight, connected to a single output node through a simple rule. If the weighted sum of inputs crosses a threshold, the output is 1. If not, the output is 0.
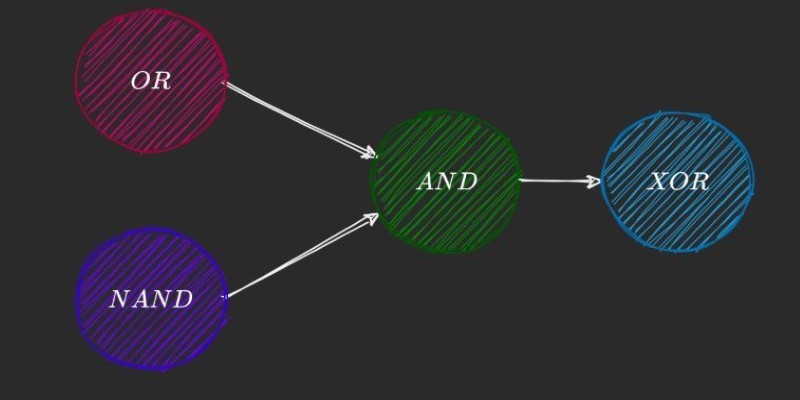
This worked fine for linearly separable problems. For example, a perceptron can easily handle logical functions like AND and OR because you can draw a straight line separating the outputs. But with XOR, there's no such line. You need something more complex to create a curved boundary or break the problem into parts.
This led to the realization that neural networks need more than one layer to handle non-linear problems like XOR. A single-layer perceptron is too limited. It can't represent the kind of logic required by XOR. The network needs to combine inputs differently before reaching the final decision.
The breakthrough came with the development of multi-layer perceptrons (MLPs), which include at least one hidden layer between the input and output. These hidden layers add complexity and give the network the power to model non-linear relationships.
In the case of XOR, adding just one hidden layer with a couple of neurons is enough. Here’s how it works in simple terms. The hidden layer transforms the inputs into a new space where XOR becomes linearly separable. You’re no longer trying to solve XOR with one line—you’re solving it by combining multiple lines in a layered way. The hidden neurons each take a piece of the problem, and the output neuron combines their responses to produce the correct result.
For example, one hidden neuron might fire when both inputs are 0 or 1, while the other fires when one input is one and the other is 0. The output neuron can then learn to interpret those patterns correctly. It’s not magic—it’s just layers transforming the data step-by-step until the answer becomes clear.
This is a small but clear example of how deep learning works. Each layer extracts patterns, transforms data, and passes it forward. With enough layers and the right functions, neural networks can model almost any function, including XOR.
Activation functions play a big role in making multi-layer networks useful. Without them, the layers would just be doing linear combinations of inputs—so no matter how many you add, the result would still be linear. That's not enough to handle XOR or any non-linear function.
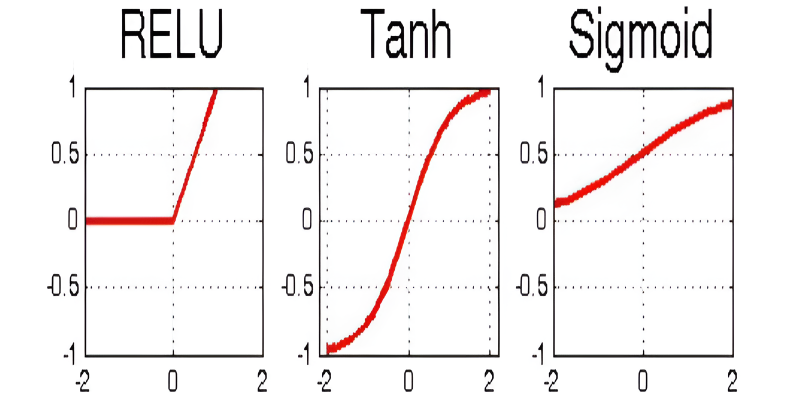
Functions like sigmoid, tanh, or ReLU are added after each layer to introduce non-linearity. This means the network can bend the decision boundary, not just push it around, which allows it to solve problems like XOR.
Learning happens through a process called backpropagation, which adjusts the weights of each connection in the network. During training, the network compares its output to the correct answer and shifts its weights slightly to reduce the error. Over time, this helps the network “learn” the function it’s trying to model.
Backpropagation and activation functions allow neural networks to solve the XOR problem—and, by extension, many other complex tasks. They're the heart of modern deep learning.
It's also worth pointing out that this shift—from simple single-layer models to multi-layer ones with non-linear functions—turned neural networks from theoretical toys into tools that power things like voice assistants, image recognition, and chatbots. And it all started with understanding XOR.
The XOR problem shows why simple neural networks fail and how adding layers makes learning possible. It marks a key moment in AI history, showing the need for depth and non-linearity. Solving XOR with a multi-layer network reveals how learning builds in steps. It's more than a logic puzzle for beginners—it's a lesson in how structure shapes intelligence. Understanding XOR helps us understand how neural networks grow from simple models into powerful learning systems.
Advertisement

Discover how to generate enchanting Ghibli-style images using ChatGPT and AI tools, regardless of your artistic abilities

Tech leaders face hurdles in developing reliable AI agents due to complexity, scalability, and integration issues.

How Python handles names with precision using namespaces. This guide breaks down what namespaces in Python are, how they work, and how they relate to scope

Learn how DreamBooth fine-tunes Stable Diffusion to create AI images featuring your own subjects—pets, people, or products. Step-by-step guide included

AWS launches AI chatbot, custom chips, and Nvidia partnership to deliver cost-efficient, high-speed, generative AI services

Discover how clean data prevents AI failures and how Together AI's tools automate quality control processes.

How DeepSeek LLM: China’s Latest Language Model brings strong bilingual fluency and code generation, with an open-source release designed for practical use and long-context tasks

How to fine-tune a Tiny-Llama model using Unsloth in this comprehensive guide. Explore step-by-step instructions on setting up your environment, preparing datasets, and optimizing your AI model for specific tasks

How Direct Preference Optimization improves AI training by using human feedback directly, removing the need for complex reward models and making machine learning more responsive to real-world preferences

RAG combines search and language generation in a single framework. Learn how it works, why it matters, and where it’s being used in real-world applications

Understand how the Python range() function works, how to use its start, stop, and step values, and why the range object is efficient in loops and iterations

Still unsure about Git push and pull? Learn how these two commands help you sync code with others and avoid common mistakes in collaborative projects