Advertisement
If you've tried making AI images of someone specific—a pet, a product, a person—you already know how things go. You type a prompt and get decent art, but it's never quite them. It's like asking a stranger to draw your childhood home from memory. That's because tools like Stable Diffusion know what a "cat" or a "sofa" generally looks like, but they don't know your cat or that sofa in your living room.
DreamBooth changes this. It trains Stable Diffusion to remember specific subjects so you can generate personalized images with them. Not just close guesses but visually accurate recreations in all kinds of settings and styles. It's still AI art—but with your context baked in.
DreamBooth isn't a standalone AI model. It's a training method applied to an existing model like Stable Diffusion. What it does is pretty clever. You feed in a few photos of your subject—let's say your orange tabby named Milo. Then you pick a unique name for him, like "zxpcat." DreamBooth fine-tunes Stable Diffusion, so it now links that new token with Milo's look.
The result? When you type something like “zxpcat wearing a bow tie” or “zxpcat in a Pixar-style animation,” you get images where Milo shows up, looking like himself—same eyes, same fur pattern, same vibe.
DreamBooth doesn't erase or replace what Stable Diffusion already knows. It just nudges it slightly, so one placeholder word is now tied to your subject. That's why it only needs a few photos, not hundreds. The base model already knows what cats look like—it just needs help spotting the difference between any cat and your cat.
Using DreamBooth takes a few steps, but it’s not overly technical once you get the hang of it. Most of the work happens up front when you’re training the model. After that, generating personalized images is as easy as writing a sentence.
Before training, you need to choose a unique label for your subject. This is what the model will use later to recall your specific person, pet, or object. Most people choose a rare combo like “sksface” or “zxpwatch” to make sure it doesn’t get confused with general words. You’ll use this token in your prompts after training.
You don’t need a lot of images—just 4 to 10 clear photos of your subject. Aim for variety: different angles, lighting conditions, facial expressions (if it’s a person), or poses (if it’s a pet or an item). Make sure the background isn’t distracting. These photos teach the model what’s unique about your subject.
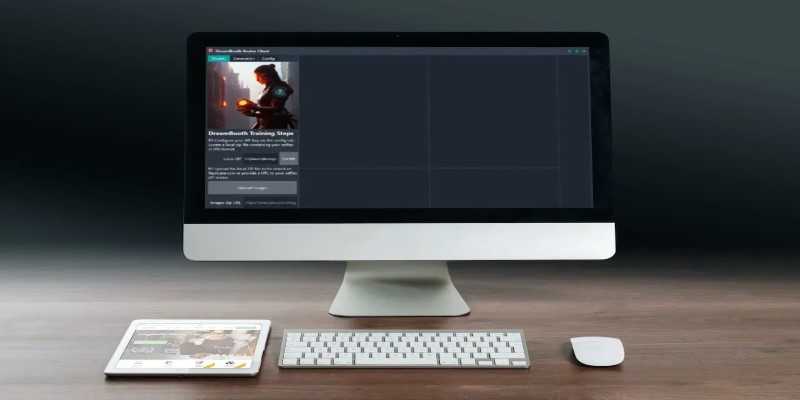
Training can be done locally if you have a strong GPU, or you can use Google Colab notebooks that others have already built for DreamBooth. You upload the photos, assign your custom token, and start the training process.
The script works by comparing your photos to more generic images of that subject type. It adjusts the model's internal weights just enough so it links the custom token with your subject—without disrupting what the model already knows. Training usually takes 30 to 90 minutes, depending on hardware.
Once training is finished, you can start generating. Just use your custom token in a prompt. For example:
The model will keep the details it learned during training while blending them into the new context you described. And because Stable Diffusion can interpret so many prompt styles—from sketches to oil paintings to product shots—you get a wide range of results.

DreamBooth shines when your subject is visually distinct. Faces, pets, and certain branded objects usually work great. It doesn’t need a giant dataset, and it’s surprisingly good at generalizing across new scenes while keeping your subject recognizable.
The catch? Overfitting. If your training images all look the same—same pose, same angle—the model gets stuck. You’ll notice all the generated results look identical. This is why having a bit of variety in your training images is key. Even subtle differences help.
Another thing: keep your token truly unique. If you name your subject “bluecar,” the model might pull from generic blue cars it’s already seen, blending them with your subject. That’s why a made-up token works better.
And while DreamBooth is powerful, it’s not flawless. Some generated images might be slightly off—like a warped eye or a smudged detail—but overall, the results are remarkably sharp for how little training data it uses.
Once your subject is trained into the model, you can get creative fast. People use it for personal, commercial, and artistic reasons. Some just want to see their dog in a space suit. Others are using it for consistent characters in web comics. Product designers might create multiple renderings of a single object in different settings without staging physical shoots.
Common uses include:
It saves time, especially in projects that need consistency. You don’t need to describe your subject over and over. The model remembers it every time, and all you need to do is focus on the new idea or setting.
DreamBooth models can also be mixed with other tools. For example, you can pair your DreamBooth model with ControlNet to control poses or layout or use inpainting to fine-tune parts of an image. Once you've added your subject, the whole toolkit of Stable Diffusion becomes more useful.
DreamBooth doesn’t add complexity to AI art—it adds clarity. You don’t have to settle for generic outputs or keep uploading references. The model learns your subject once, then keeps it in memory, ready to place it anywhere you want. That’s what sets it apart.
For people who already use Stable Diffusion and want to push things further, DreamBooth offers an easy way to make images that feel personal and consistent. It's simple and fast, and the results speak for themselves.
Advertisement

Gemma 3 mirrors DSLMs in offering higher value than LLMs by being faster, smaller, and more deployment-ready

Learn how DreamBooth fine-tunes Stable Diffusion to create AI images featuring your own subjects—pets, people, or products. Step-by-step guide included

Discover how OpenAI's Sora sets a new benchmark for AI video tools, redefining content creation and challenging top competitors

Need to convert a Python list to a NumPy array? This guide breaks down six reliable methods, including np.array(), np.fromiter(), and reshape for structured data

How Python’s classmethod() works, when to use it, and how it compares with instance and static methods. This guide covers practical examples, inheritance behavior, and real-world use cases to help you write cleaner, more flexible code
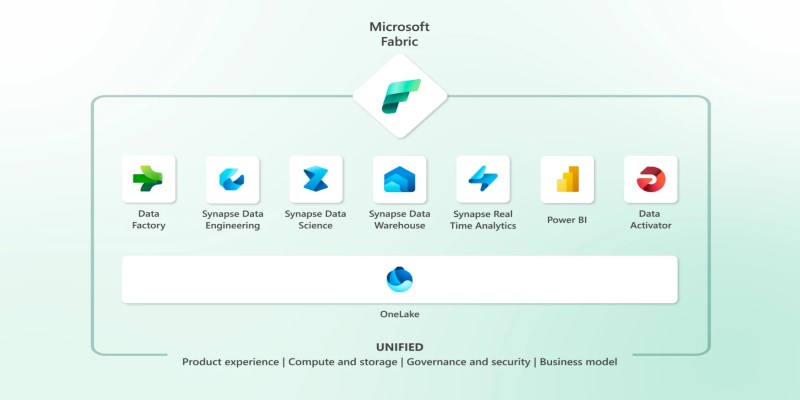
Explore Microsoft Fabric, a unified platform that connects Power BI, Synapse, Data Factory, and more into one seamless data analytics environment for teams and businesses
Explore the XOR Problem with Neural Networks in this clear beginner’s guide. Learn why simple models fail and how a multi-layer perceptron solves it effectively

Learn the top 7 impacts of the DOJ data rule on enterprises in 2025, including compliance, data privacy, and legal exposure.

RAG combines search and language generation in a single framework. Learn how it works, why it matters, and where it’s being used in real-world applications

How to create Instagram Reels using Predis AI in minutes. This step-by-step guide shows how to turn ideas into high-quality Reels with no editing skills needed

How to fine-tune a Tiny-Llama model using Unsloth in this comprehensive guide. Explore step-by-step instructions on setting up your environment, preparing datasets, and optimizing your AI model for specific tasks
Transform any website into an AI-powered knowledge base for instant answers, better UX, automation, and 24/7 smart support