Advertisement
Model deployment usually feels like a cycle that never ends. Each new version or fine-tuned model calls for its deployment pipeline, its own endpoints, and a fresh set of resources. Multiply that by dozens of models, and suddenly, you're stuck managing infrastructure rather than experimenting with ideas. TGI Multi-LoRA breaks that pattern. With just one deployment, you can serve up to 30 LoRA-adapted models without needing to juggle multiple copies or containers. It keeps things lean and simple—and doesn't cut corners.
LoRA, or Low-Rank Adaptation, makes fine-tuning large language models more practical. Instead of training every parameter in a massive model, it works by adding small matrices that get trained while keeping the base model frozen. This method drastically reduces training time and storage, which has already helped teams fine-tune small datasets or tasks quickly.
But there’s been a catch: if you’ve fine-tuned multiple LoRAs for different tasks—say sentiment analysis, summarization, and Q&A—you’ve had to load and manage each of them like separate models. That means more memory, more processing overhead, and more endpoints. TGI Multi-LoRA eliminates all that.
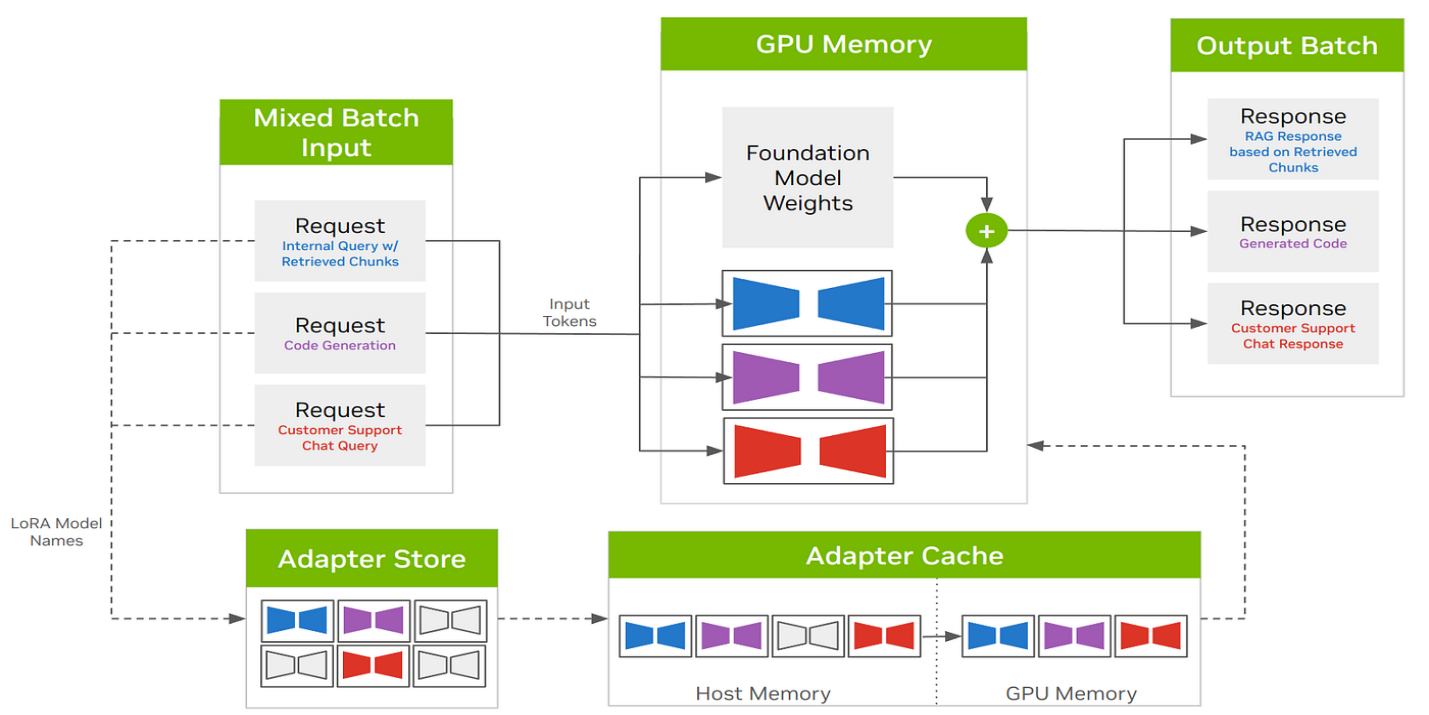
With this, you load the base model once. You upload each LoRA adapter separately. Then, at runtime, you pick which LoRA you want to activate for a request. That’s it. The main model doesn’t get duplicated. The memory overhead is marginal. And response times? They stay where they should be.
At its core, TGI (Text Generation Inference) with Multi-LoRA extends the Hugging Face TGI server to allow dynamic LoRA switching. Here's how it works step-by-step:
So, you don't just save memory—you also maintain performance.
The clearest benefit is in deployment. Instead of setting up 30 containers to serve 30 LoRA models, you set up one. That saves time, compute, and money. But the upside goes beyond infrastructure.
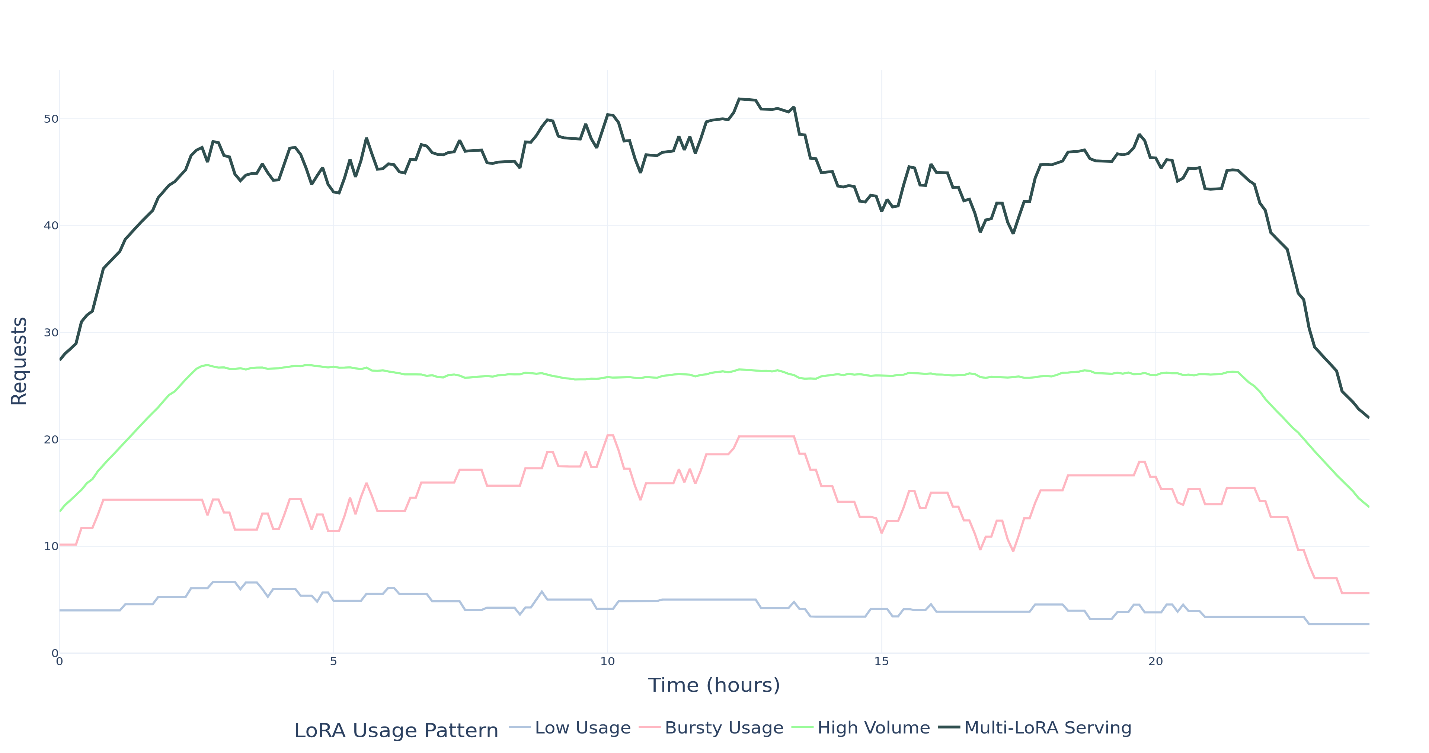
Traditional setups required loading each LoRA-merged model into memory. Multiply that by 10, 20, or 30, and you're quickly hitting resource ceilings. With Multi-LoRA, the base is loaded once, and adapters are only a fraction of the full size. This means you can serve more models with the same resources.
If you're switching between models mid-session—say in a multi-tenant setup—this method keeps things snappy. There's no need to reload full models or spin up new containers. The LoRA weights are small and load fast, so switching tasks or users doesn’t slow anything down.
Instead of exposing multiple endpoints for different fine tunes, you maintain one. This simplifies API management and reduces the chance of routing errors. Each request just includes a tag to indicate the right LoRA. Clean, scalable, and straightforward.
If your team is trying out different adapters, TGI Multi-LoRA allows you to upload and test them without requiring a full redeployment. This shortens the feedback loop, making experimentation smoother. You don't have to freeze everything just to test a small change in tone or style.
Getting started isn’t complex, but there are a few key steps to follow. Here’s how to go from a base model and some LoRA files to a fully working Multi-LoRA setup with TGI.
Start by downloading your chosen base model—LLaMA, Falcon, or a similar model—from Hugging Face. Make sure TGI supports it. You'll want the standard format, not one with merged LoRA weights.
Place the model in a directory that your TGI server can access. This is the foundation for all your LoRA variants.
Each LoRA fine-tune should be stored in its directory. These directories should include the adapter configuration files and weight tensors. You don't merge these with the base model. Keep them separate.
Assign a unique name or ID to each adapter. This will be used later to route requests properly.
You’ll need the TGI version that includes Multi-LoRA support. Once installed, launch the server with the following arguments:
bash
CopyEdit
text-generation-launcher \
--model-id /path/to/base-model \
--lora-dir /path/to/lora-adapters \
--max-num-loras 30
This tells TGI to expect LoRA adapters in the specified folder and allows up to 30 to be loaded at once.
Now, to use a specific adapter, include its ID in your API call. Here’s a sample payload:
json
CopyEdit
{
"inputs": "Summarize this article...",
"parameters": {
"lora_id": "summarizer_v1"
}
}
TGI applies the adapter weights, runs inference, and returns the result. The base model stays loaded the entire time.
TGI Multi-LoRA solves a real problem that gets in the way of deploying multiple fine-tuned models at scale. It doesn’t rely on shortcuts—it’s just efficient. Load one base, stack up your adapters, and switch between them as needed. You cut down on computing waste, simplify your endpoints, and keep performance steady. One deployment, many models. And it works.
Advertisement

Can you really run a 7B parameter language model on your Mac? Learn how Apple made Mistral 7B work with Core ML, why it matters for privacy and performance, and how you can try it yourself in just a few steps

How to create Instagram Reels using Predis AI in minutes. This step-by-step guide shows how to turn ideas into high-quality Reels with no editing skills needed

RAG combines search and language generation in a single framework. Learn how it works, why it matters, and where it’s being used in real-world applications

NPC-Playground is a 3D experience that lets you engage with LLM-powered NPCs in real-time conversations. See how interactive AI characters are changing virtual worlds

Discover how to generate enchanting Ghibli-style images using ChatGPT and AI tools, regardless of your artistic abilities

Understand how the Python range() function works, how to use its start, stop, and step values, and why the range object is efficient in loops and iterations

What if you could deploy dozens of LoRA models with just one endpoint? See how TGI Multi-LoRA lets you load up to 30 LoRA adapters with a single base model

Still unsure about Git push and pull? Learn how these two commands help you sync code with others and avoid common mistakes in collaborative projects

Need to convert a Python list to a NumPy array? This guide breaks down six reliable methods, including np.array(), np.fromiter(), and reshape for structured data

Discover how OpenAI's Sora sets a new benchmark for AI video tools, redefining content creation and challenging top competitors

Find how Flux Labs Virtual Try-On uses AI to change online shopping with realistic, personalized try-before-you-buy experiences

Gemma 3 mirrors DSLMs in offering higher value than LLMs by being faster, smaller, and more deployment-ready